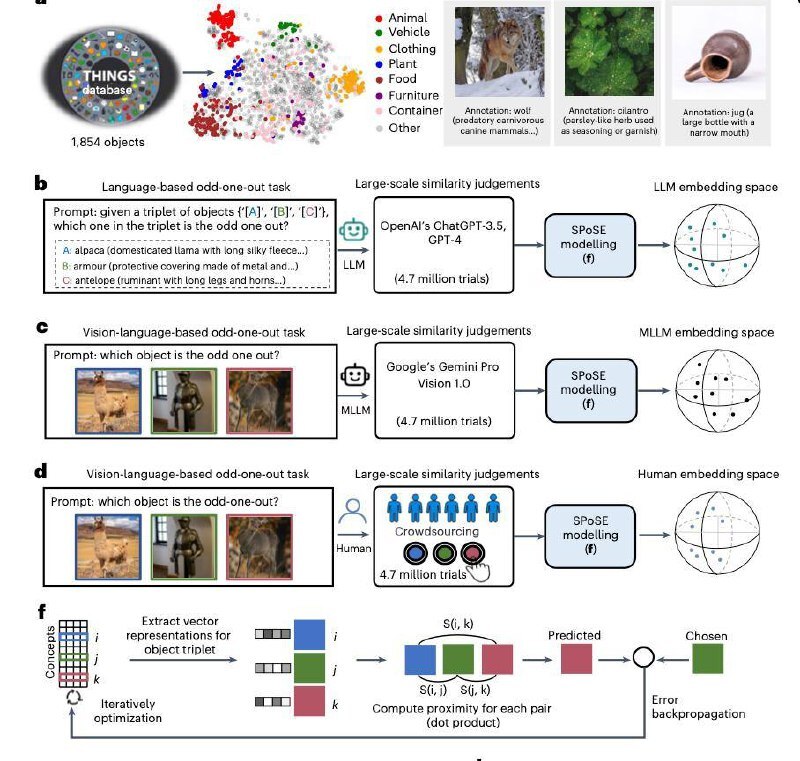
Учёные провели эксперимент, сравнив восприятие 1854 объектов из базы THINGS. Людям и моделям (ChatGPT-3.5, Llama3.1, Gemini Pro Vision 1.0, Qwen2\_VL-7B) показывали наборы из трёх предметов и задавали простой вопрос: «Какой здесь лишний?»
Собрали аж 4,7 миллиона ответов и на их основе выстроили «ментальное пространство» (по сути, embeddings в 66 измерениях), чтобы понять, насколько близко восприятие моделей к человеческому.
Вот что получилось:
- Корреляция между восприятием объектов у LLM и людей оказалась на уровне 0.71, у мультимодальных моделей — 0.85, а между самими людьми — 0.9. Уже неплохо, хотя и не идеально.
- Чтобы объяснить 95% решений, моделям достаточно всего 3–8 скрытых признаков, тогда как человеку нужно 7–13. Модели воспринимают вещи проще и усреднённее.
- Из 66 измерений у моделей легко интерпретируются 60 (например: животное, еда, температура, ценность), а у людей таких 62.
- Модели чуть хуже ловят визуальные детали (цвета и мелкие признаки), зато отлично разбираются в смыслах и категориях.
- Самое крутое: когда embeddings моделей сравнили с паттернами мозговой активности (по данным МРТ людей), оказалось, что в ключевых областях мозга модели практически так же близки к человеку, как другой человек!
- В задаче на классификацию объектов LLM показали 83.4% точности, мультимодальные — 78.3%, а люди — 87.1%.
- А ещё у всех трёх систем (человека, LLM и MLLM) совпали 38 из 66 скрытых измерений.
Что это значит для нас? А то, что наши «ментальные карты» с моделями отличаются, и промты стоит подстраивать под те «оси», по которым LLM лучше понимают задачу. То есть меньше эмоций, больше категорий и конкретики.
Вот несколько советов на основе исследования:
- Чётко и кратко: Сразу давайте модели главное — 3–5 ключевых понятий. Исследование показало, что больше ей особо не нужно, она и так поймёт суть.
- Смыслы важнее деталей: Используйте чёткие семантические категории («спорткар», «фрукт», «инструмент»), а не художественные описания. LLM больше опираются на смыслы, люди — на визуальные нюансы.
- Просите уточнять категории: Чтобы получить структурированный ответ, задавайте вопросы через конкретные признаки. У моделей хорошо сформированы понятные категории типа животного, еды, транспорта, твёрдости и температуры.
- Убирайте «воду»: Чем меньше субъективных описаний, тем лучше. 95–99% производительности достигается на 3–8 признаках, остальное только путает.
Кстати, в основной задаче «кто тут лишний» LLM показали точность 56.7%, мультимодальные модели — 63.4%, а люди — 64.1% (при случайных 33.3%). То есть модели и правда мыслят примерно как мы.
Попробуйте применить этот подход на практике и напишите, заметили ли вы, что ответы стали ближе к тому, как думает человек? Может, есть и собственные лайфхаки, интересно будет посмотреть?
Оригинал: пост в Telegram · подписаться на «Готовим ИИшницу»